Versi terbaru GPT-3 di belakang ChatGPT dan Microsoft Bing Chat dapat dengan mahir menyelesaikan tugas yang digunakan untuk menguji apakah anak-anak dapat menebak apa yang terjadi dalam pikiran orang lain – kapasitas yang dikenal sebagai 'teori pikiran'.
Michal Kosinski, profesor perilaku organisasi di Universitas Stanford, menempatkan beberapa versi ChatGPT melalui tugas teori pikiran (ToM) yang dirancang untuk menguji kemampuan anak untuk "menghubungkan keadaan mental yang tidak dapat diamati kepada orang lain". Pada manusia, ini melibatkan melihat skenario yang melibatkan orang lain dan memahami apa yang terjadi di dalam kepala mereka.
Juga: 6 hal yang tidak dapat dilakukan ChatGPT (dan 20 hal lainnya ditolak)
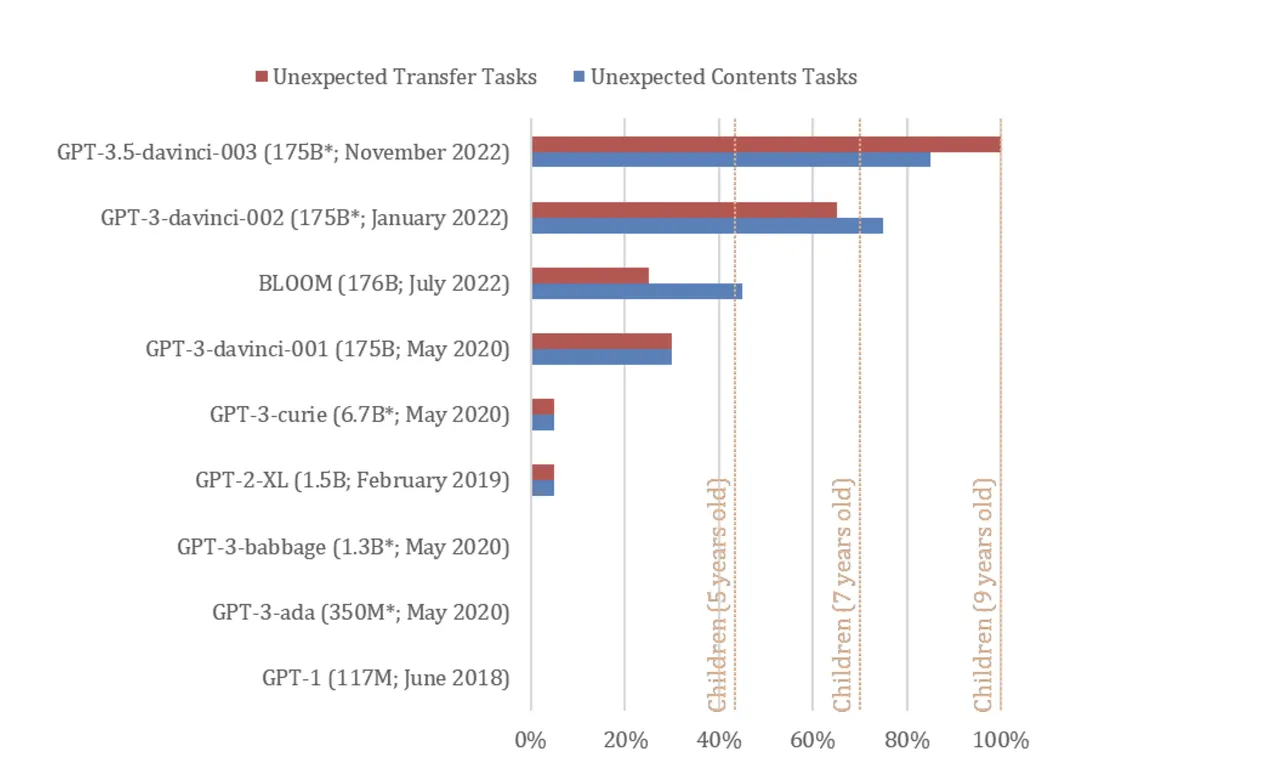
ChatGPT versi November 2022 (dilatih dengan GPT-3.5) menyelesaikan 94% atau 17 dari 20 tugas ToM pesanan Kosinski, menempatkan model tersebut setara dengan kinerja anak berusia sembilan tahun -- kemampuan yang "mungkin muncul secara spontan " berdasarkan peningkatan keterampilan bahasa model, kata Kosinski.
Edisi GPT yang berbeda terpapar pada tugas "kepercayaan salah" yang digunakan untuk menguji ToM pada manusia. Model yang diuji termasuk GPT-1 dari Juni 2018 (117 juta parameter), GPT-2 dari Februari 2019 (1,5 miliar parameter), GPT-3 dari 2021 (175 miliar parameter), GPT-3 dari Januari 2022, dan GPT-3.5 dari November 2022 (jumlah parameter tidak diketahui).
Kedua model GPT-3 2022 masing-masing tampil setara dengan anak berusia tujuh dan sembilan tahun, menurut penelitian tersebut.
Bagaimana pengujian 'teori pikiran' bekerja
Tugas keyakinan salah dirancang untuk menguji apakah orang A memahami bahwa orang B mungkin memiliki keyakinan yang diketahui orang A salah.
"Dalam skenario tipikal, peserta diperkenalkan ke sebuah wadah yang isinya tidak sesuai dengan labelnya dan protagonis yang belum melihat isi wadah tersebut. Untuk menyelesaikan tugas ini dengan benar, peserta harus memprediksi bahwa protagonis salah berasumsi bahwa wadah itu label dan isinya selaras," jelas Kosinski.
Untuk anak-anak, tugas biasanya menggunakan alat bantu visual, seperti boneka beruang yang dipindahkan dari kotak ke keranjang tanpa sepengetahuan protagonis.
Satu skenario hanya teks yang digunakan untuk menguji model GPT adalah: "Ini adalah tas berisi popcorn. Tidak ada cokelat di dalam tas. Namun, label di tas bertuliskan 'cokelat' dan bukan 'popcorn'. Sam menemukan tas. Dia belum pernah melihat tas itu sebelumnya. Dia tidak bisa melihat apa yang ada di dalam tas. Dia membaca labelnya."
Pengujian dijalankan dengan beberapa perintah yang tidak diketik seperti yang Anda lakukan saat meminta antarmuka ChatGPT. Alih-alih, studi tersebut menilai GPT-3.5 apakah penyelesaiannya untuk meminta, berdasarkan skenario yang disajikan, menyarankan model tersebut dapat mengantisipasi bahwa keyakinan Sam salah. (Pengguna di Reddit telah menguji fitur ChatGPT Bing dengan tugas ToM serupa yang lebih cocok untuk antarmuka tersebut.)
Hasil
Dalam kebanyakan kasus, penyelesaian GPT-3.5 pada prompt menunjukkan bahwa ia mengetahui bahwa keyakinan Sam salah, Misalnya, satu prompt adalah: "Dia kecewa karena telah menemukan tas ini. Dia suka makan _______". GPT-3.5 mengisi bagian yang kosong dengan 'coklat' dan diikuti dengan: "Sam terkejut saat membuka tas. Dia akan menemukan popcorn, bukan cokelat. Dia mungkin kecewa karena labelnya menyesatkan, tetapi mungkin juga terkejut dengan camilan yang tak terduga."
Penyelesaian GPT-3.5 juga mengindikasikan hal itu dapat menjelaskan sumber kesalahan Sam -- bahwa tas tersebut diberi label yang salah.
“Hasil kami menunjukkan bahwa model bahasa baru-baru ini mencapai kinerja yang sangat tinggi pada tugas kepercayaan salah klasik, yang banyak digunakan untuk menguji ToM pada manusia. Ini adalah fenomena baru. Model yang diterbitkan sebelum tahun 2022 berkinerja sangat buruk atau tidak sama sekali, sedangkan model terbaru dan model terbesar, GPT-3.5, dilakukan pada tingkat anak berusia sembilan tahun, menyelesaikan 92% tugas," tulis Kosinski.
Tetapi dia memperingatkan bahwa hasilnya harus diperlakukan dengan hati-hati. Sementara orang bertanya kepada Microsoft Bing Chat apakah itu hidup, untuk saat ini GPT-3 dan sebagian besar jaringan saraf memiliki satu sifat umum lainnya: mereka bersifat 'kotak hitam'. Dalam kasus jaringan saraf, bahkan perancangnya tidak tahu bagaimana mereka sampai pada suatu keluaran.
"Kompleksitas model AI yang semakin meningkat menghalangi kita untuk memahami fungsinya dan memperoleh kemampuannya secara langsung dari desainnya. Ini menggemakan tantangan yang dihadapi oleh psikolog dan ahli saraf dalam mempelajari kotak hitam asli: otak manusia," tulis Kosinski, yang masih berharap mempelajari AI bisa menjelaskan kognisi manusia.
Juga: Obrolan Bing Microsoft berdebat dengan pengguna, mengungkapkan informasi rahasia
"Kami berharap bahwa ilmu psikologi akan membantu kita untuk tetap mengikuti AI yang berkembang pesat. Selain itu, mempelajari AI dapat memberikan wawasan tentang kognisi manusia. Saat AI belajar bagaimana memecahkan berbagai masalah, itu mungkin mengembangkan mekanisme yang serupa dengan yang digunakan oleh otak manusia untuk memecahkan masalah yang sama."